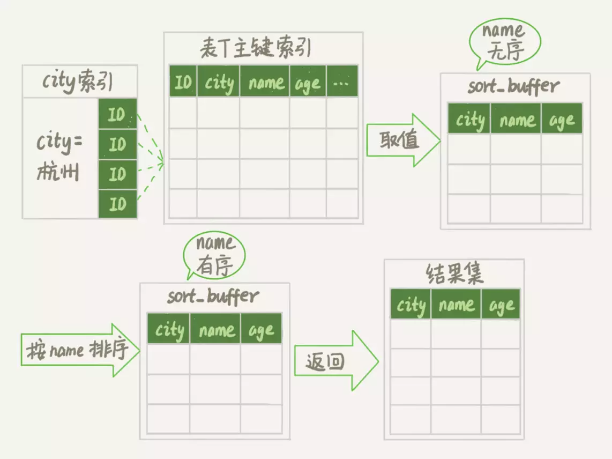
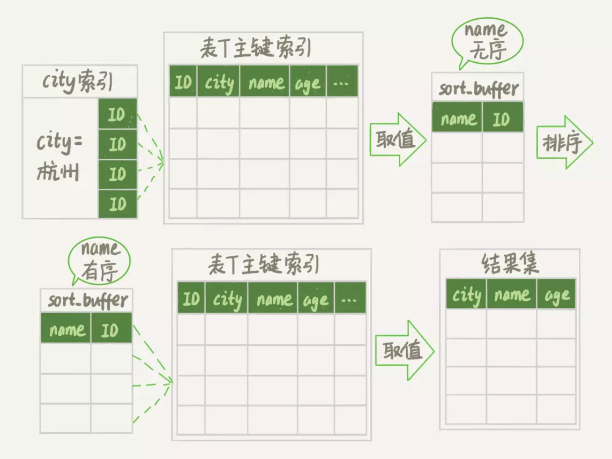
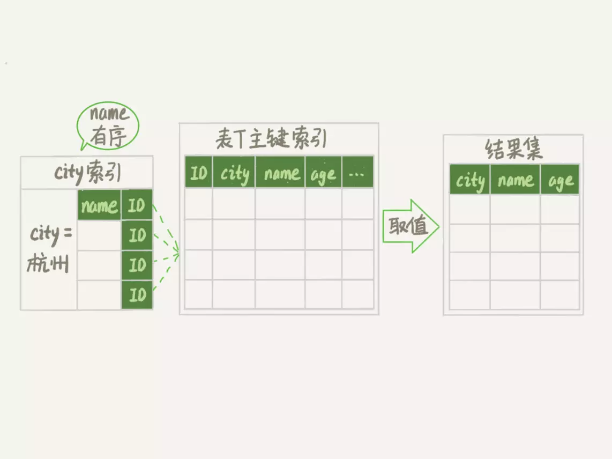
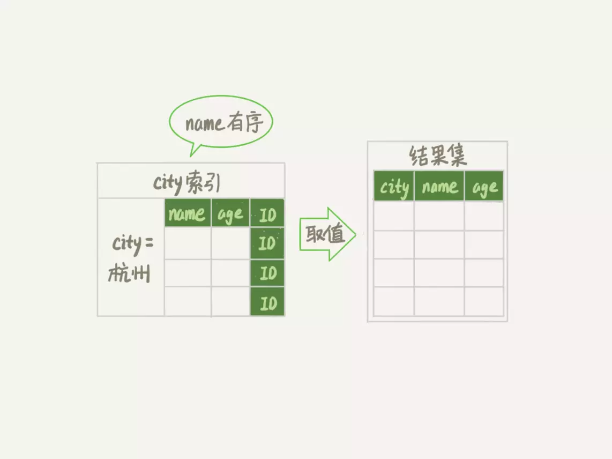
alter table t add index city_user_age(city, name, age);
Extra 字段里面多了“Using index”,表示的就是使用了覆盖索引,性能上会快很多。
使用索引优化排序的时候,一定要注意查询条件,和排序的字段,要满足最左匹配原则。
索引失效排查
背景
最近项目在做性能测试,返现一个慢sql的问题。
性能测试反馈如下sql存在性能问题
1 2 3 4 5 6 7
主要为sql数据查询耗时, SQL1:select * from wecall_task_call where account_key = "xingnengyace1" and task_id = 2041 and call_status = 1 order by call_time DESC limit 30; 耗时8ms SQL2:select * from wecall_task_call where account_key = "xingnengyace1" and task_id = 2041 and call_status = 0 order by call_time DESC limit 30; 耗时18288ms
ALTER TABLE wecall_task_call ADD INDEX `IDX_AK_TASKID_CALLSTATUS_CALLTIME`(`account_key`,`task_id`,`call_status`,`call_time`); DROP INDEX `IDX_TASK_STATUS` ON wecall_task_call;
修改后的表结构sql如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
CREATE TABLE `wecall_task_call_v1` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID', `account_key` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT 'account_key', `task_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '任务id', `cid` bigint(20) NOT NULL DEFAULT '0' COMMENT '客户id', `call_id` varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '唯一标识用户通话id', `call_status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '呼叫状态 0待呼叫 1已呼叫', `import_time` bigint(20) NOT NULL DEFAULT '0' COMMENT '导入时间', `call_time` bigint(20) NOT NULL DEFAULT '0' COMMENT '通话时间', `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `IDX_TASK_CALLID` (`account_key`,`call_id`) USING BTREE, KEY `IDX_TASK_CID` (`account_key`,`task_id`,`cid`) USING BTREE, KEY `IDX_CALL` (`account_key`,`call_time`) USING BTREE, KEY `IDX_AK_TASKID_CALLSTATUS_CALLTIME`(`account_key`,`task_id`,`call_status`,`call_time`) ) ENGINE=InnoDB AUTO_INCREMENT=142607 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='通话详情表'
select * from wecall_task_call force index(IDX_AK_TASKID_CALLSTATUS_CALLTIME) where account_key = "xingnengyace1" and task_id = 2041 and call_status = 0 order by call_time DESC limit 30