健康检查API模式
有时服务看上去正在运行,但它却无法处理请求。例如,新启动的服务实例可能尚未准备好接受请求。例如某个服务大约需要10秒钟来初始化消息和数据库适配器。
在它们准备好之前,部署基础设施将HTTP请求路由到服务实例是没有意义的。
此外,服务实例可能会失败却不自动终止。例如某个服务进程已经Hang住了。部署基础设施不应将请求路由到已失败但仍在运行的服务实例。
并且,如果服务实例无法恢复,则部署基础设施必须终止它并创建新实例。
使用健康检查时需要考虑两个问题。
第一个是接口的实现,它必须报告服务实例的健康状况。
第二个问题是如何配置部署基础设施以调用健康检查接口。
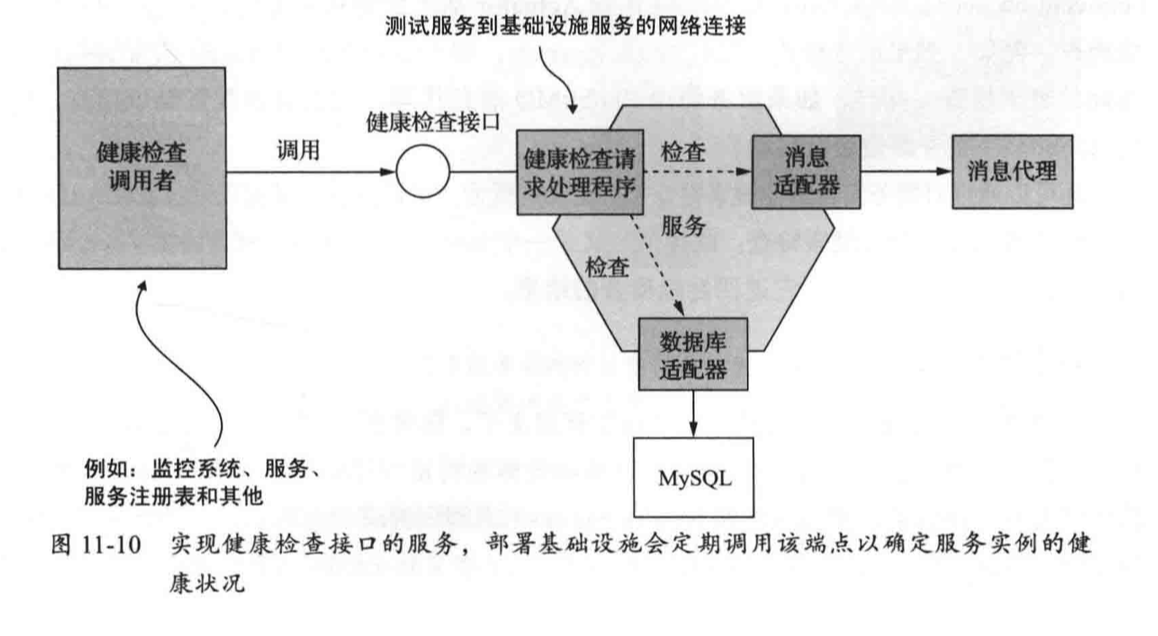
实现健康检查接口
实现健康检查接口的代码必须以某种方式确定服务实例的健康状况。
一种简单的方法是验证服务实例是否可以访问其外部基础设施服务。
具体做法取决于具体的基础设施服务,例如可以通过获取数据库连接,并执行测试查询来验证服务是否已连接到数据库。
调用健康检查接口
如果没有人调用它,健康检查接口就没有意义了。
部署服务时,必须配置部署基础设施以调用接口。如何执行此操作取决于部署基础设施的特定详细信息。
部署基础设施
- Docker
- Kubernetes
- NDP
- noah
springboot的健康检查
Spring Boot Actuator是健康检查库的一个很好的例子。
它实现了/actuator/health接口,实现此接口的代码负责返回健康状况检查的结果。通过使用约定优于配置(convention over configuration),Spring Boot Actuator基于部署基础设施实现了一组合理的健康检查。
例如,如果服务使用JDBC DataSource,则Spring Boot Actuator会配置执行测试查询的健康检查。
同样,如果服务使用RabbitMQ消息代理,它会自动配置健康检查,以验证RabbitMO服务器是否已启动。
还可以通过对服务实现其他健康检查来自定义此行为。可以通过定义实现HealthIndicator接口的类来实现自定义健康检查。此接口定义了一个health()方法,该方法由/actuator/health接口的实现调用。它返回健康检查的结果。
业务平滑上下线与健康检查
大部分的互联网业务场景下,需要对用户提供7x24小时服务。尤其是我们的应用发布频次频繁的情况下,降低发布时对用户的影响,提升用户体验。应用引入应用健康检查的支持。
所谓平滑上下线,也是应用提供相应的online,offline接口,由部署基础设施调用。从而让应用感知到上线,下线请求,主动将自己从注册中心摘除,防止新流量进入,并处理完已经接受的请求之后,平稳关闭。
基于k8s的部署平台
Kubernetes提供了自愈的能力,当容器崩溃,K8s能够自动重启这个容器。为了更好利用K8s故障自愈能力,并且实现优雅停机。业务需在代码中实现以下健康检查接口,提供HTTP访问。
健康检查一共需要实现4个HTTP接口,在发布过程与容器运行中起作用:
- check接口**(存活探针)**:
- 发布过程中检查业务进程是否启动完成
- 作为K8s Liveness存活探针,在Pod运行过程中由kubelet执行探测,若探测失败达到阈值,容器将会被自动重启 【接口响应的状态码应大于等于200且小于400,视为探测成功】
- online接口:
- 发布过程中check接口返回200之后,启动脚本将自动调用online接口,online接口返回200意味着进程已就绪,可以接收流量了
- status接口(业务探针):
- 标识业务进程是否运行正常。发布过程中在online接口成功之前,status接口返回非200;online成功之后返回200
- 作为K8s Readiness业务就绪探针,在Pod运行过程中由kubelet执行探测,若探测失败达到阈值,容器将不再接收流量 【接口响应的状态码应大于等于200且小于400,视为探测成功】
- 参考后续网络配置文档:
- 当使用K8s Service时,会被从service的endpoint中移除
- 当使用Nginx Upstream时,会被从upstream中移除
- offline接口:
- 作为Pod prestop,在容器销毁前将会被调用,提供业务在容器销毁前的扩展钩子
业务启动流程
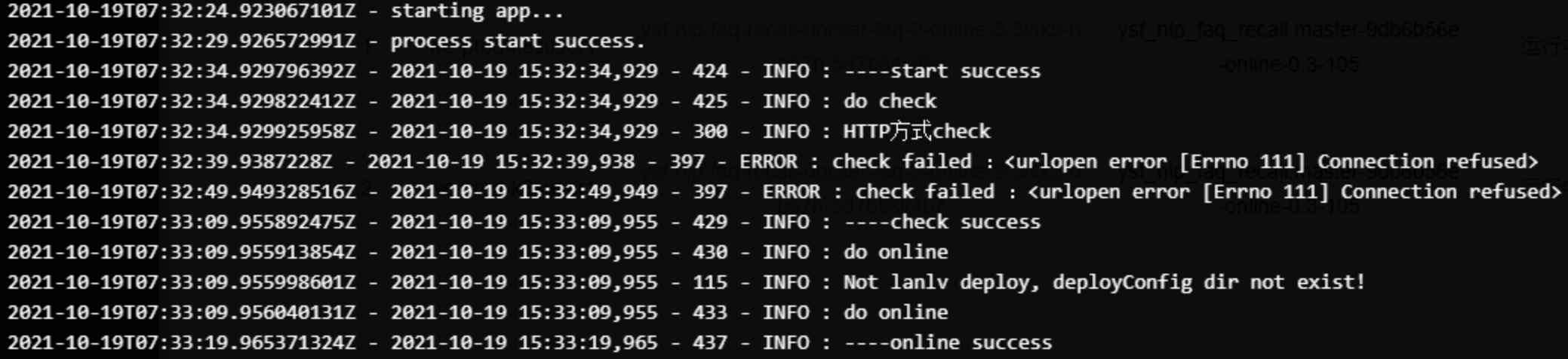
下图为业务启动过程中发布日志示例,依次是
- starting app:启动业务进程
- do check:轮询check接口,直至成功或超过次数限制
- check success:check接口返回成功,业务进程完成启动
- do online:调用online接口,激活系统
- online success:业务系统开始接收流量,status接口返回200
Nginx的健康检查
被动健康检查
Nginx自带有健康检查模块:ngx_http_upstream_module,可以做到基本的健康检查,配置如下:
1 | upstream cluster{ |
Nginx只有当有访问时后,才发起对后端节点探测。如果本次请求中,节点正好出现故障,Nginx依然将请求转交给故障的节点,然后再转交给健康的节点处理。所以不会影响到这次请求的正常进行。但是会影响效率,因为多了一次转发,而且自带模块无法做到预警。
主动健康检查
主动地健康检查,nignx定时主动地去ping后端的服务列表,当发现某服务出现异常时,把该服务从健康列表中移除,当发现某服务恢复时,又能够将该服务加回健康列表中。
淘宝有一个开源的实现nginx_upstream_check_module模块官网:http://tengine.taobao.org/document_cn/http_upstream_check_cn.html