update的加锁流程
加锁规则总结
因为间隙锁在可重复读隔离级别下才有效,以下规则基于可重复读隔离级别。(RC级别下,去掉间隙锁这块逻辑就可以了)
- 加锁的基本单位是next-key lock。next-key lock是前开后闭区间。
- 查找过程中访问到的对象才会加锁。
- 索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁。
- 索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁。
- 唯一索引上的范围查询会访问到不满足条件的第一个值为止。
表t的建表语句和初始化语句如下:
1 | CREATE TABLE `t` ( |
等值查询间隙锁

- 表t中没有id=7的记录
- 加锁单位是next-key lock,session A加锁范围就是(5,10];
- 这是一个等值查询(id=7),而id=10不满足查询条件,next-key lock退化成间隙锁,因此最终加锁的范围是(5,10)
- session B要往这个间隙里面插入id=8的记录会被锁住,但是session C修改id=10这行是可以的。
非唯一索引等值锁
第二个例子是关于覆盖索引上的锁
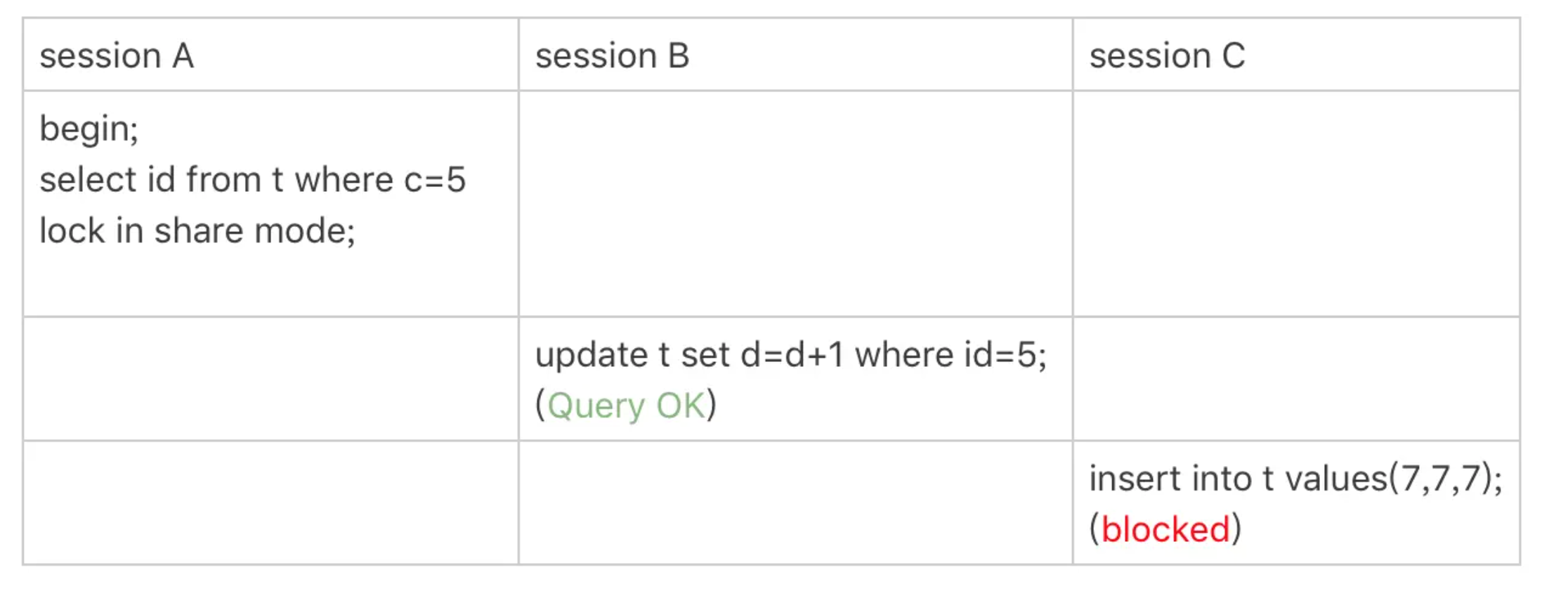
- session A要给索引c上c=5的这一行加上读锁。
- 加锁单位是next-key lock,因此会给(0,5]加上next-key lock。
- 继续向右遍历,查到c=10才放弃。访问到的都要加锁,因此要给(5,10]加next-key lock。
- 最后一个值不满足c=5这个等值条件,因此退化成间隙锁(5,10)
- 至此session A 共获取了 (0,5],(5,10)两个间隙锁。
- 只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁,session B的update语句可以执行完成。
- session C要插入一个(7,7,7)的记录,就会被session A的间隙锁(5,10)锁住。
lock in share mode只锁覆盖索引,但是如果是for update就不一样了。 执行 for update时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。
如果你要用lock in share mode来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段。比如,将session A的查询语句改成select d from t where c=5 lock in share mode。(效果同上,即c索引上的(0,5],(5,10)两个间隙锁,以及主键id上的所有符合条件的c=5的行锁。)
主键索引范围锁
对于我们这个表t,下面这两条查询语句,加锁范围相同吗?
1 | mysql> select * from t where id=10 for update; |
sql1 分析如下
- 开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。 根据优化1, 主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁。
sql2分析如下

- 开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。 根据优化1, 主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁。
- 唯一索引上的范围查询会访问到不满足条件的第一个值为止,找到id=15这一行停下来,因此需要加next-key lock(10,15]。
- session A这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15]。
非唯一索引范围锁
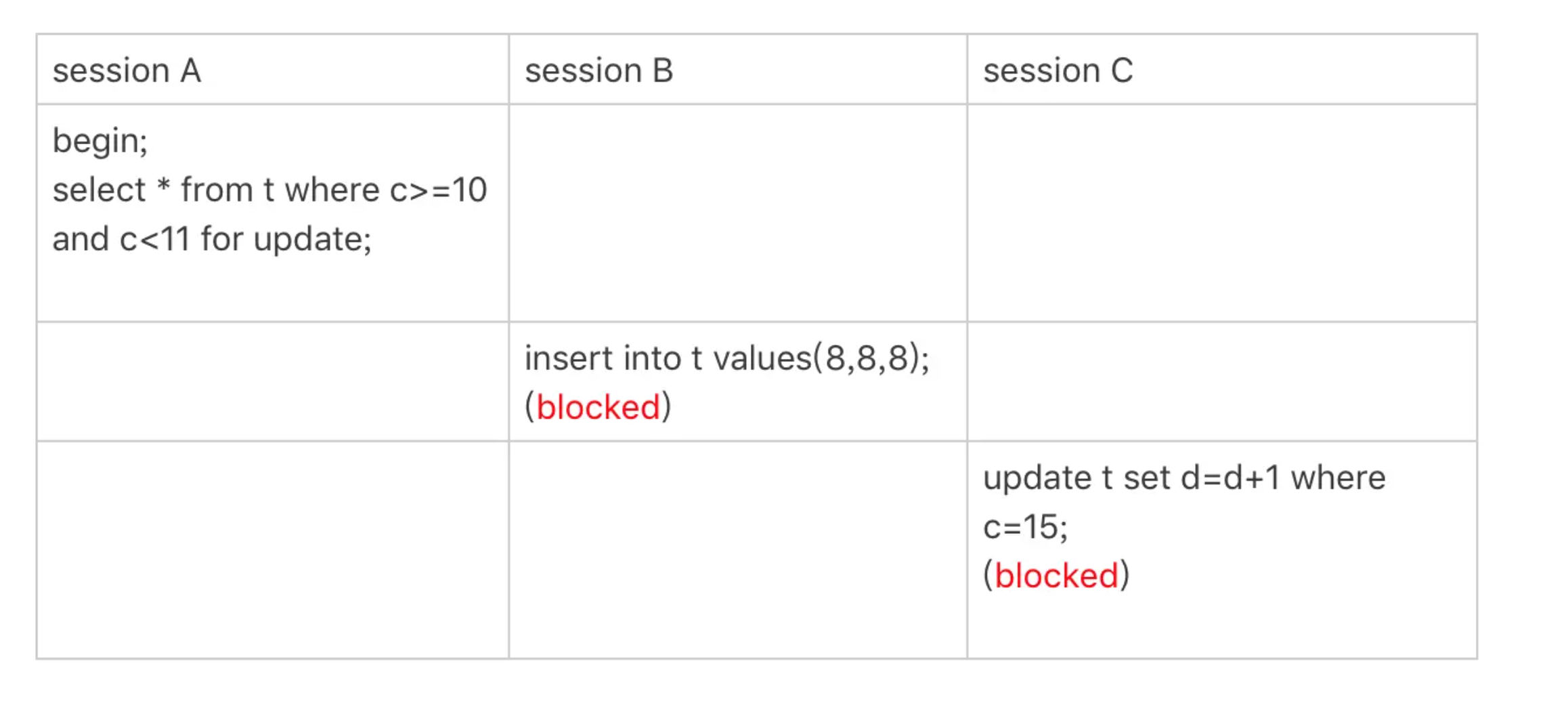
- 在第一次用c=10定位记录的时候,索引c上加了(5,10]这个next-key lock后,由于索引c是非唯一索引,没有优化规则,也就是说不会蜕变为行锁,
- 最终sesion A加的锁是,索引c上的(5,10] 和(10,15] 这两个next-key lock。
- 需要扫描到c=15才停止扫描,是合理的,因为InnoDB要扫到c=15,才知道不需要继续往后找了。
唯一索引范围锁bug
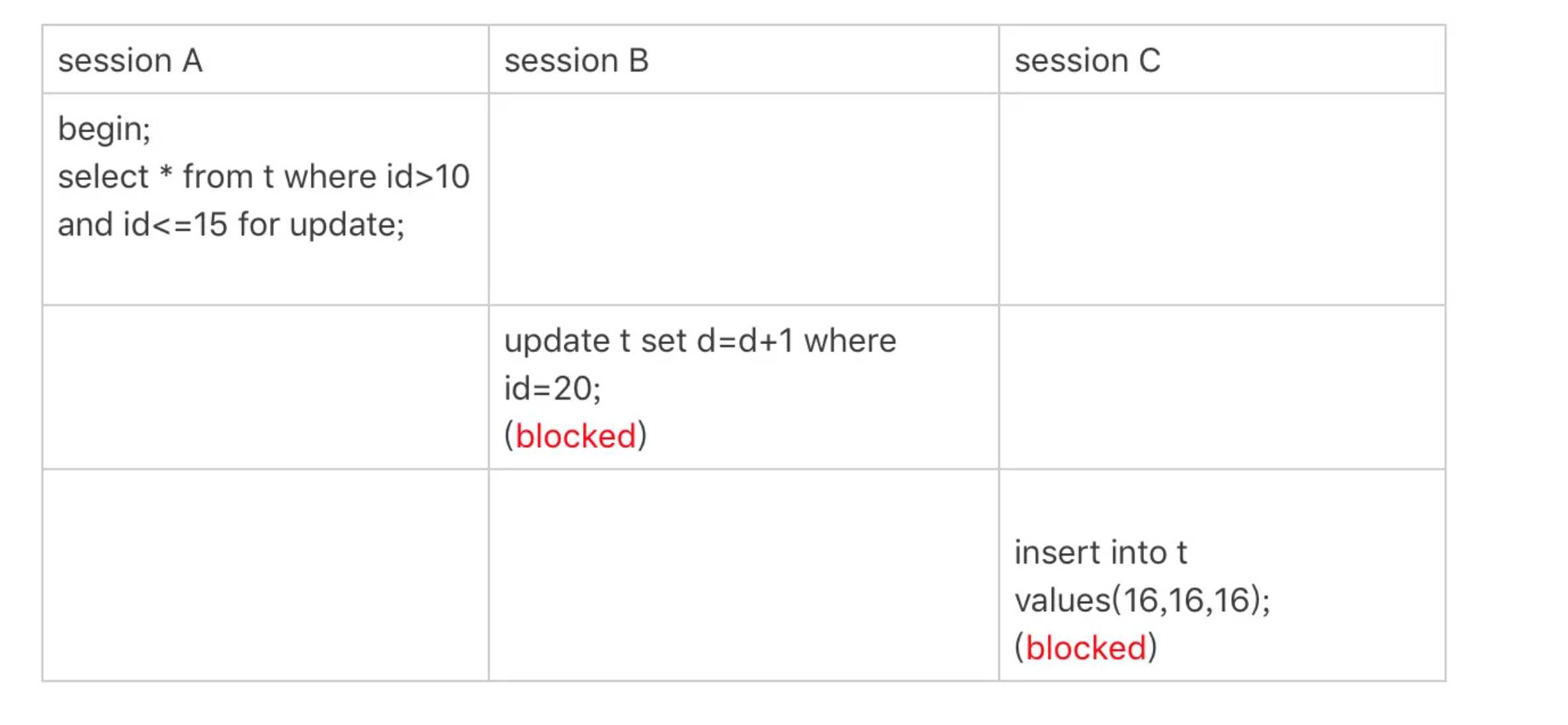
session A是一个范围查询,按照原则1的话,应该是索引id上只加(10,15]这个next-key lock,并且因为id是唯一键,所以循环判断到id=15这一行就应该停止了。
但是实现上,InnoDB会往前扫描到第一个不满足条件的行为止,也就是id=20。而且由于这是个范围扫描,因此索引id上的(15,20]这个next-key lock也会被锁上。
照理说,这里锁住id=20这一行的行为,其实是没有必要的。因为扫描到id=15,就可以确定不用往后再找了。但实现上还是这么做了。
非唯一索引上存在”等值”的例子
1 | mysql> insert into t values(30,10,30); |

- session A在遍历的时候,先访问第一个c=10的记录。同样地,根据原则1,在c上加(5,10] next-key lock。
- session A向右查找找到第一个不满足的c=10的记录,在c上加(10,15]next-key lock。
- 这是一个等值查询,(10,15]next-key lock会退化成(10,15)的间隙锁
- 此时c共持有(5,10] 和[10,15) 两个间隙锁
limit 语句加锁
基于上述案例,增加limit
1 | mysql> insert into t values(30,10,30); |

- delete语句明确加了limit 2的限制,满足条件的语句已经有两条,循环就结束了
- 索引c上的加锁范围就变成了(5,10]
sessionB 改成 update t set d = 4 where id = 40,也可以执行,不会被锁住,因为已经满足条件了,(id=40,c=10)这一行数据并不会加上行锁。
index merge导致的死锁
什么是index merge
index merge 是使用索引进行优化的重要基础之一。
我们的 where 中可能有多个条件(或者join)涉及到多个字段,它们之间进行 AND 或者 OR,那么此时就有可能会使用到 index merge 技术。index merge 技术如果简单的说,其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)。
查看index merge是否开启
1 | mysql> SELECT @@optimizer_switch\G |
数据准备
1 | CREATE TABLE `t` ( |
执行sql explain select * from t where c= 25 and d=25

说明使用了index merge。
死锁是怎样产生的
sql1 update t set e = 10 where c= 25 and d = 25
sql2 update t set e = 11 where c= 20 and d = 30
因为使用了index merge,sql1 可能先在c上申请锁,然后再申请d上的锁。
sql2同时执行,由于存在index merge,索引上的加锁顺序不能确定。可能会先申请d上的锁,然后再申请c上的锁。
这样两个sql就出现了死锁的情况。
如何避免出现死锁
本例中是由于Index Merge同时使用2个索引方向加锁所导致,解决方法也比较简单,就是消除因index merge带来的多个索引同时执行的情况。
- 利用force index(idx_skucode)强制走某个索引,这样InnoDB就会忽略index merge,避免多个索引同时加锁的情况。
- 禁用Index Merge,这样InnoDB只会使用两个索引中的一个,所有事物加锁顺序都一样,不会造成死锁。
- 既然Index Merge同时使用了2个独立索引,我们不妨新建一个包含这两个索引所有字段的联合索引,这样InnoDB就只会走这个单独的联合索引,这其实和禁用index merge是一个道理。
- 通过条件,捞取对应数据的主键id,任何通过主键id去更新,可以保证锁的最小化。