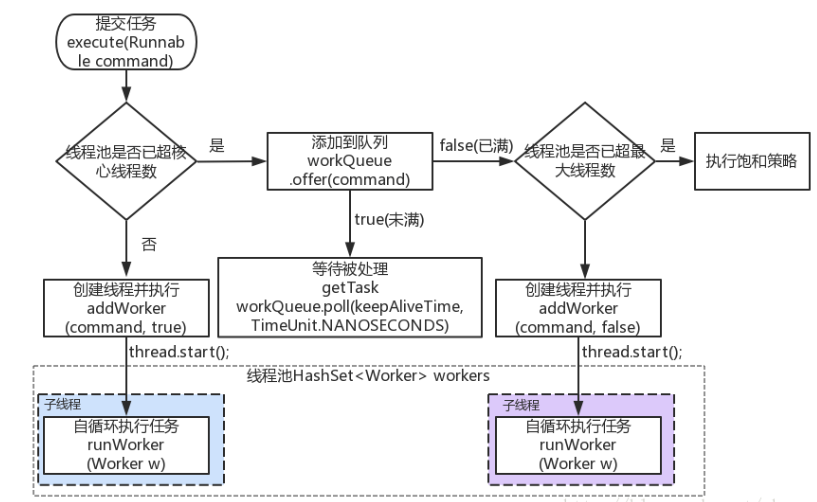
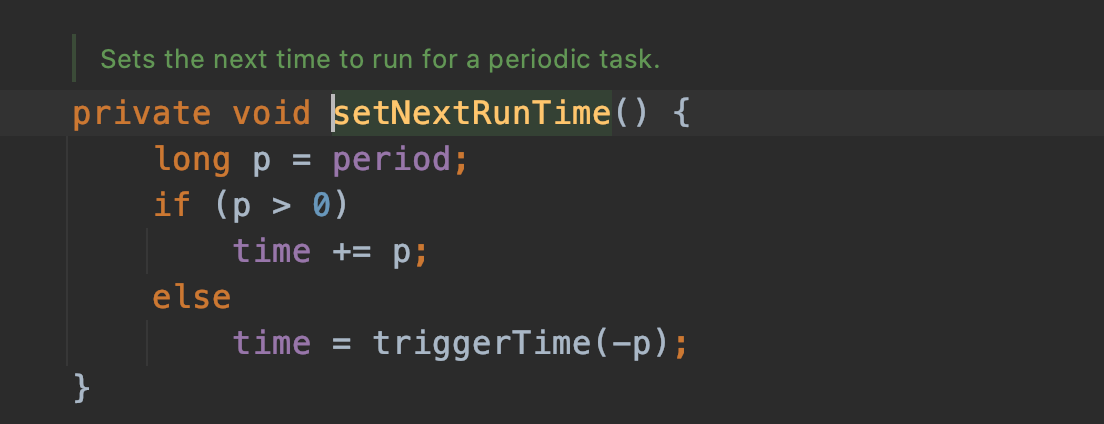
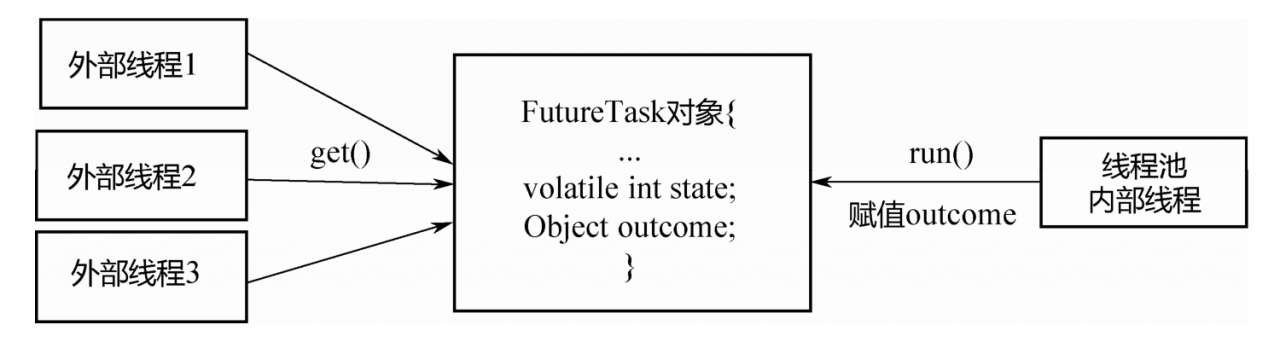
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. */ int c = ctl.get(); // 判断有没有达到核心线程数,没达到直接调用addWorker方法,增加线程数 if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) // 直接加worker成功,直接返回即可 return; c = ctl.get(); } // addWorker失败,可能的原因有 // 1. 线程池状态不是running了 // 2. 外部并发调用execute,导致worker数量已经超过了corePoolSize // 所以对线程池进行状态检查,并将任务加入队列 if (isRunning(c) && workQueue.offer(command)) { // 任务入队的时候,线程池状态可能发生变化,所以需要再次检查 // 如果再次检查发现线程池状态不是running了,需要将刚加进去的任务移除掉,并调用reject方法 int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) // 如果线程池还是running,但是没有线程运行任务了,需要补偿一个worker addWorker(null, false); } else if (!addWorker(command, false)) // 如果队列满了 加入队列失败,需要增加一个非核心worker // 如果增加成功,就没什么问题,如果增加失败,调用reject reject(command); }
private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { //循环调用以下流程 // 1. 判断线程池状态 // 2. 获取当前worker数量 // 满足线程条件,增加workerCnt,并继续往下创建线程 int c = ctl.get(); int rs = runStateOf(c);
// Check if queue empty only if necessary. if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false;
for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } //开始创建worker流程 boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException(); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true; } } } finally { //如果运行worker失败,需要减少workerCnt if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
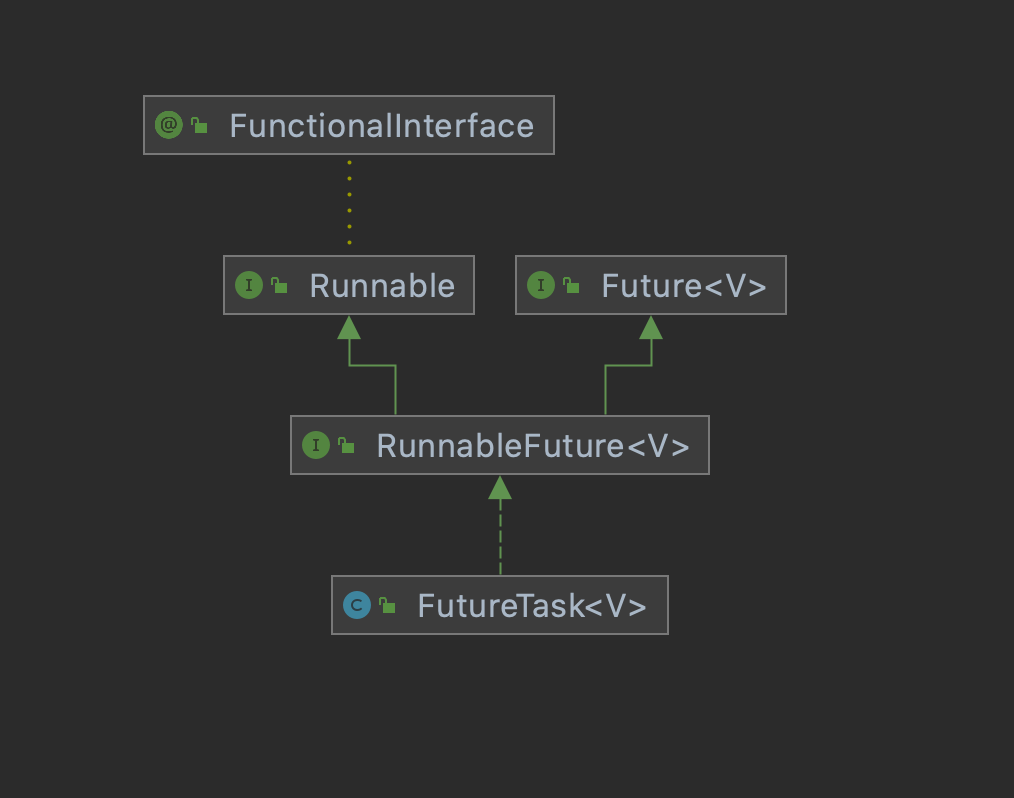
private final class Worker extends AbstractQueuedSynchronizer implements Runnable { /** * This class will never be serialized, but we provide a * serialVersionUID to suppress a javac warning. */ private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */ final Thread thread; /** Initial task to run. Possibly null. */ Runnable firstTask; /** Per-thread task counter */ volatile long completedTasks;
/** * Creates with given first task and thread from ThreadFactory. * @param firstTask the first task (null if none) */ Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); }
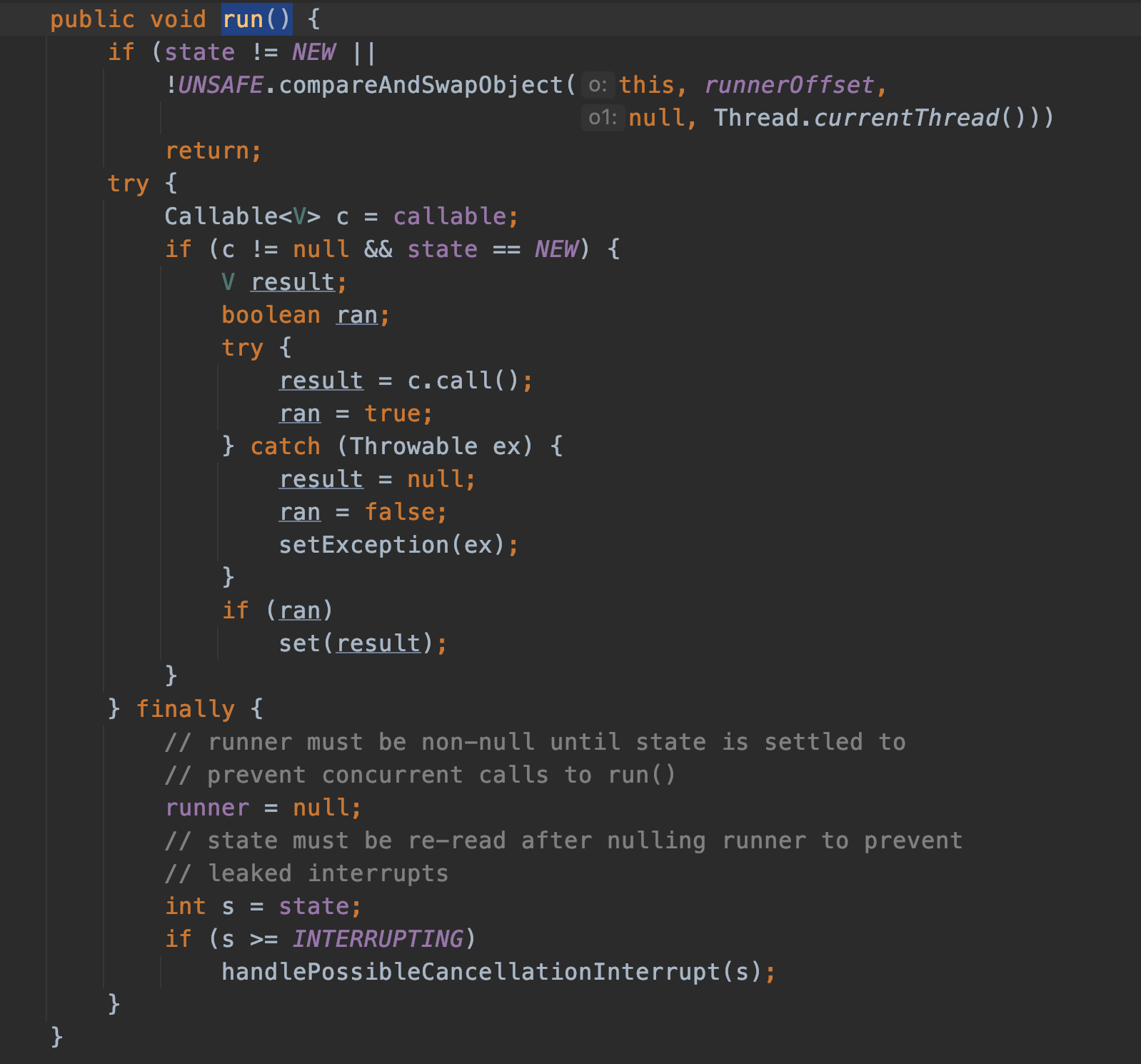
/** Delegates main run loop to outer runWorker */ public void run() { runWorker(this); }