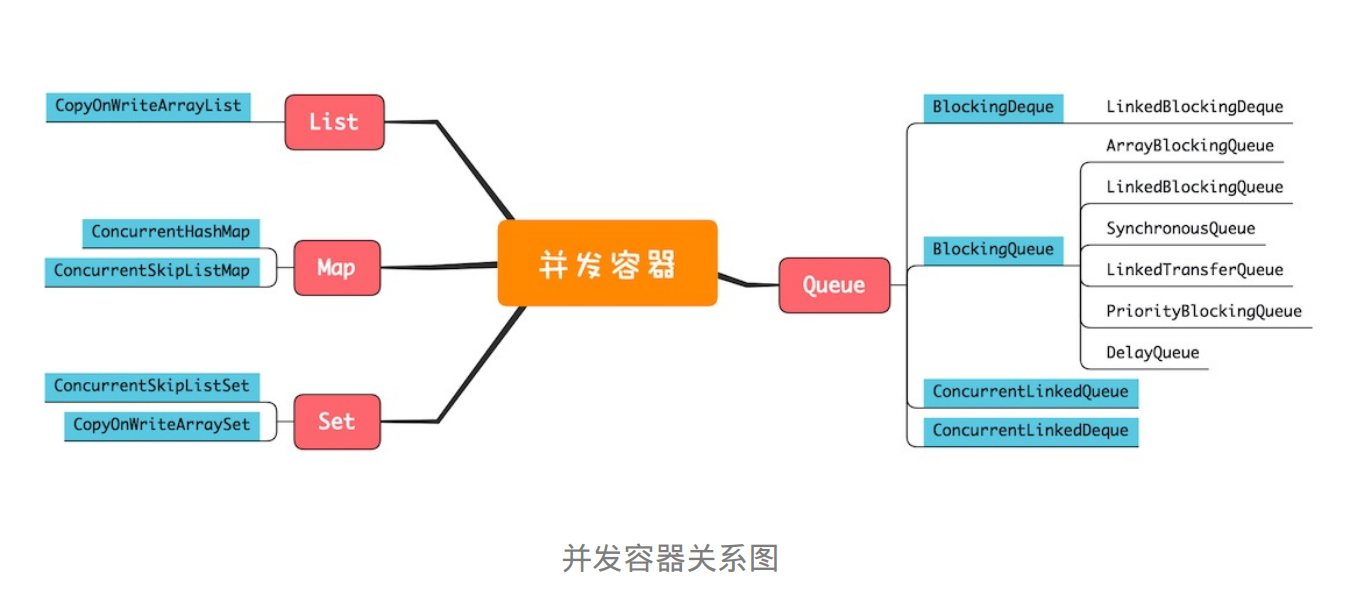
使用Collections创建线程安全的类
内部实现原理就是用了代理模式,传入map对象,调用每个map对象前都用synchronized关键字进行同步。
远古时代的线程安全容器(Java同步容器)
Hashtable
Vector
所有访问方法都加synchronized关键字
CopyOnWriteArrayList 并发包中的并发List只有CopyOnWriteArrayList
CopyOnWriteArrayList使用写时复制的策略来保证list的一致性,增删改过程中通过复制出一个快照数组,对快照数组进行增删改操作后,将指针指向修改后的快照数组上,不会对原来的数组进行修改。
获取一修改一写入三步操作并不是原子性的,所以在增删改的过程中都使用了独占锁,来保证在某个时间只有一个线程能对list数组进行修改 。
CopyOnWriteArrayList提供了弱一致性的法代器,从而保证在获取迭代器后,其他线程对list的修改是不可见的,迭代器遍历的数组是一个快照 。
ps 用CopyOnWriteArrayList的迭代器去遍历,遍历的是当前的快照数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class CopyOnWriteArrayList <E> implements List <E>, RandomAccess, Cloneable, java.io.Serializable { ..... private transient volatile Object[] array; final transient ReentrantLock lock = new ReentrantLock (); final Object[] getArray() { return array; } final void setArray (Object[] a) { array = a; } private E get (Object[] a, int index) { return (E) a[index]; } public E get (int index) { return get(getArray(), index); } public E set (int index, E element) { final ReentrantLock lock = this .lock; lock.lock(); try { Object[] elements = getArray(); E oldValue = get(elements, index); if (oldValue != element) { int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len); newElements[index] = element; setArray(newElements); } else { setArray(elements); } return oldValue; } finally { lock.unlock(); } } public Iterator<E> iterator () { return new COWIterator <E>(getArray(), 0 ); } ..... }
CopyOnWriteArraySet 基于CopyOnWriteArrayList实现的,在CopyOnWriteArrayList上包装了一层,继承了AbstractSet。
并发队列 队列常见方法
offer 在队列末尾添加一个元素,如果传递的参数是null则抛出NPE异常
add 底层调用offer
poll 在队列头部获取并移除一个元素,如果队列为空则返回null。
peek 同poll,只获取不删除
阻塞队列,增加了take()和put()方法
take(),同poll,但是会阻塞
put(),同offer 但是会阻塞
offer(e,timeout,timeUnit) 队尾添加元素,超时返回false
poll(e,timeout,timeUnit) 超时返回false
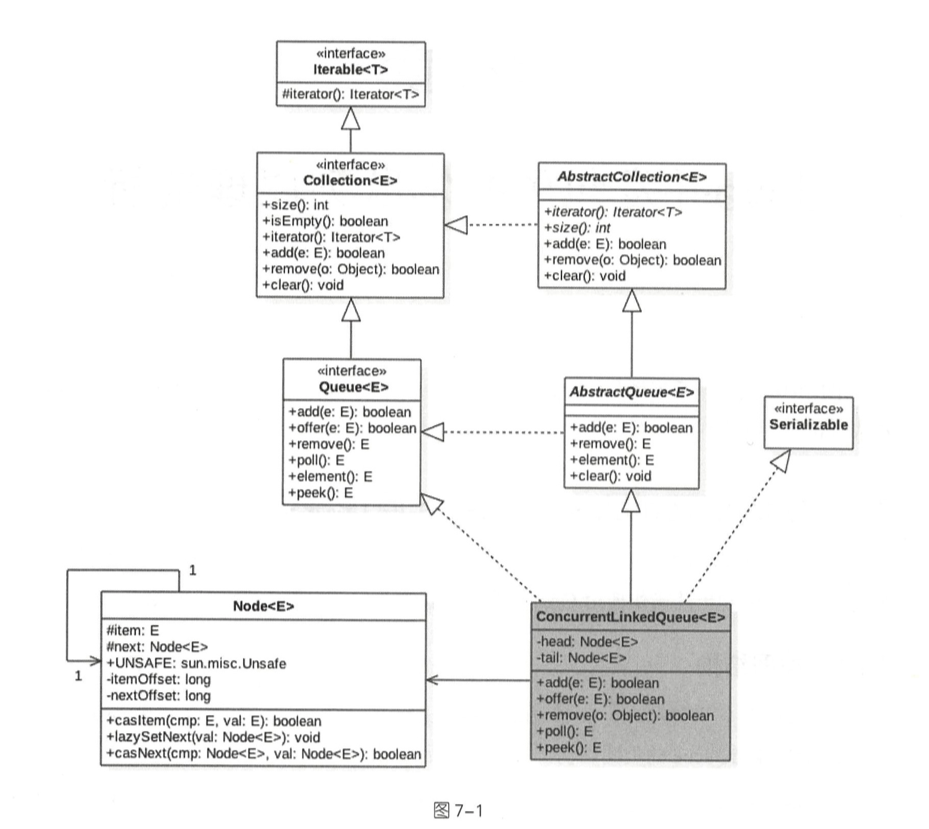
ConcurrentLinkedQueue ConcurrentLinkedQueue是线程安全 的无界 、非阻塞 队列,其底层数据结构使用单向链表实现,对于入队和出队操作使用CAS来实现线程安全。
实现Queue接口,实现队列的基本方法,通过CAS的方式来保证线程安全。由于没有时间BlockingQueue接口,没有take()等方法。
ArrayBlockingQueue 基于数组实现的有界 阻塞队列。
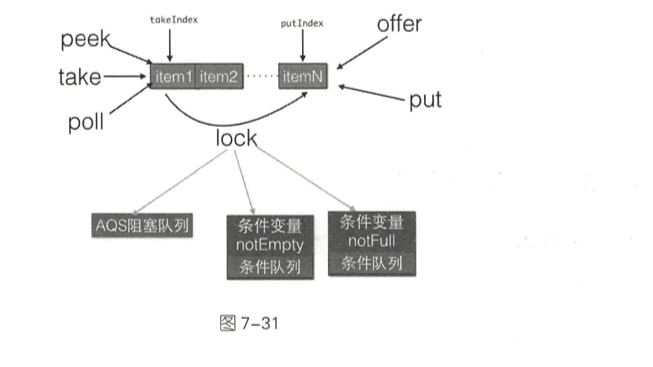
ArrayBlockingQueue的内部有一个数组items,用来存放队列元素,putindex变量表示入队元素下标,takelndex是出队下标,count统计队列元素个数。从定义可知,这些变量并没有使用volatile修饰,这是因为访问这些变量都是在锁块内,而加锁己经保证了锁块内变量的内存可见性了。另外有个独占锁lock用来保证出、入队操作的原子性,这保证了同时只有一个线程可以进行入队、出队操作。
ArrayBlockingQueue通过使用全局独占锁实现了同时只能有一个线程进行入队或者出队操作 ,这个锁的粒度比较大,有点类似于在方法上添加synchronized的意思。其中。offer和poll操作通过简单的加锁进行入队、出队操作,而put、take操作则使用条件变量实现了,如果队列满则等待,如果队列空则等待 ,然后分别在出队和入队操作中发送信号激活等待线程实现同步。
相比LinkedBlockingQueue,ArrayBlockingQueue的size操作的结果是精确的,因为计算前加了全局锁。
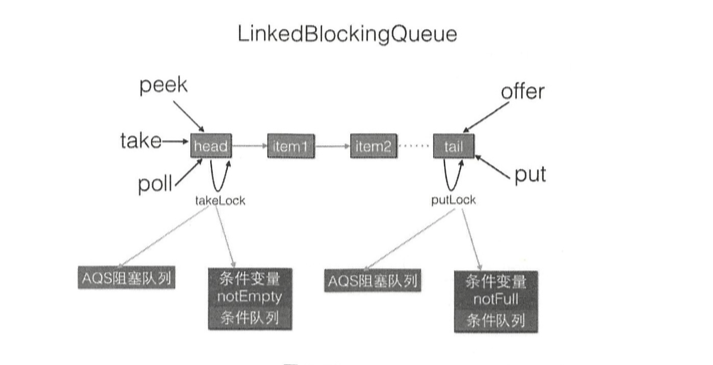
LinkedBlockingQueue LinkedBlockingQueue基于独占锁和单向链表实现的的阻塞队列。
根据构造参数,可以是有界,也可以是无界的。
LinkedBlockingDeque 双向阻塞队列
对头、尾节点的操作分别使用了单独的独占锁 从而保证了原子性,所以出队和入队操作是可以同时进行的 。另外对头、尾节点的独占锁都配备了一个条件队列,用来存放被阻塞的线程,并结合入队、出队操作实现了一个生产消费模型 。
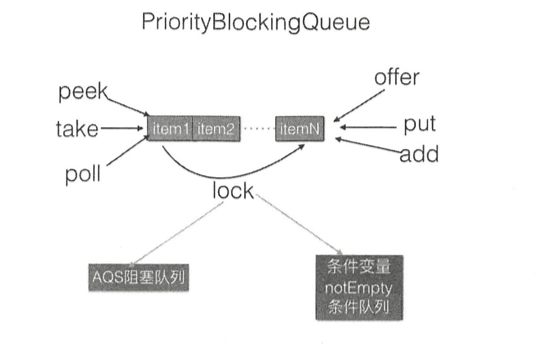
PriorityBlockingQueue PriorityBlockingQueue是带优先级 的无界 阻塞队列,每次出队都返回优先级最高或者最低的元素。其内部是使用平衡二叉树堆 实现的,所以直接遍历队列元素不保证有序。默认使用对象的compareTo方法提供比较规则,如果你需要自定义比较规则则可以自定义comparators。
lock独占锁对象用来控制同时只能有一个线程可以进行入队、出队操作 。
notEmpty条件变量用来实现take方法阻塞模式。
这里没有notFull条件变量是因为这里的put操作是非阻塞的,为啥要设计为非阻塞的,是因为这是无界队列
默认队列容量为11,默认比较器为null ,也就是使用元素的compareTo方法 进行比较来确定元素的优先级,这意味着队列元素必须实现了Comparable接口 。
当前元素个数>=最大容量时会通过CAS算法扩容,出队时始终保证出队的元素是堆树的根节点,而不是在队列里面停留时间最长的元素。
DelayQueue 1 2 3 4 5 6 7 8 9 10 11 12 public interface Delayed extends Comparable <Delayed> { long getDelay (TimeUnit unit) ; }
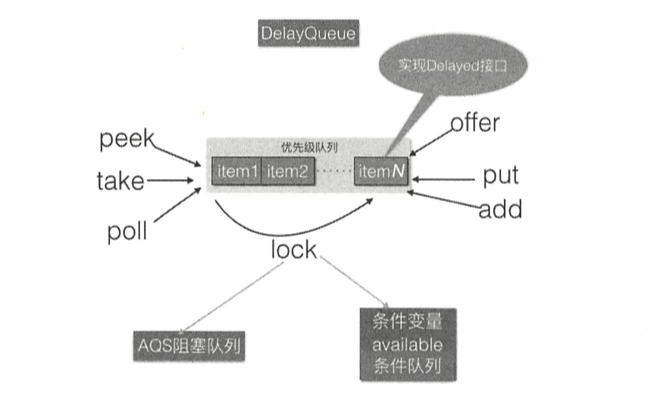
DelayQueue并发队列是一个无界阻塞延迟队列 ,队列中的每个元素都有个过期时间,当从队列获取元素时,只有过期元素才会出队列 。队列头元素是最快要过期的元素。
DelayQueue内部使用PriorityQueue存放数据 ,使用ReentrantLock实现线程同步。另外,队列里面的元素要实现Delayed接口,由于每个元素都有一个过期时间,所以要实现获知当前元素还剩下多少时间就过期了的接口,由于内部使用优先级队列来实现,所以要实现元素之间相互比较的接口。
SynchrousQueue synchronousQueue是一个没有数据缓冲的阻塞队列,生产者线程对其的插入操作put()必须等待消费者的移除操作take()(可以理解为长度为1的有界队列)。
内部没有用直接用AQS,而是用CAS的方式实现锁实现了自己的等待队列
支持公平和非公平两种模式 。
1 2 3 4 5 6 7 8 9 10 11 12 public static ExecutorService newCachedThreadPool (ThreadFactory threadFactory) { return new ThreadPoolExecutor (0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue <Runnable>(), threadFactory); }
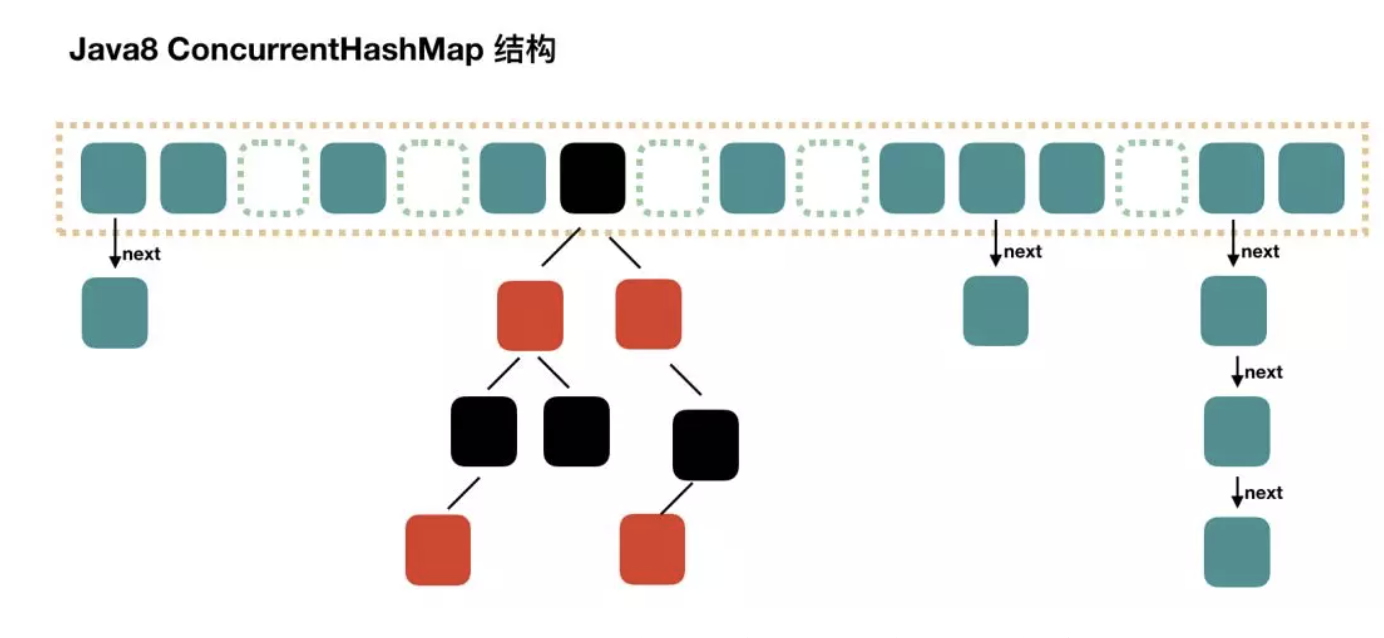
ConcurrentHashMap 不安全的HashMap hashMap死循环问题
jdk7中的hashMap扩容的时候,在头部插入数据,多线程环境下会出现死锁的情况。
jdk8中采用尾插法解决了死循环问题,但是还是存在节点丢失的情况。
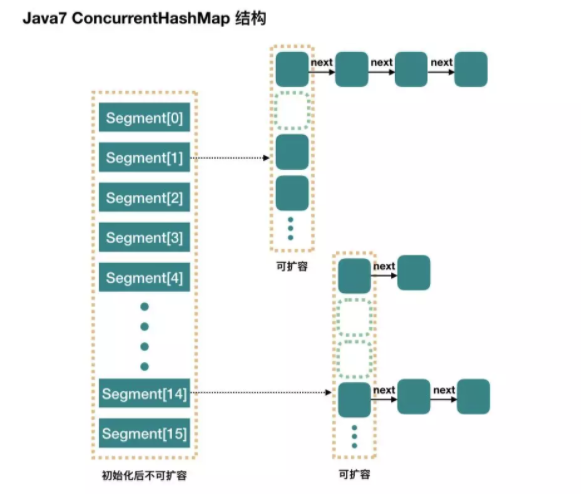
jdk7 ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
concurrencyLevel:并行级别、并发数、Segment 数,默认是 16(2的幂次方),初始化后不会再扩容。
Segment内部类似HashMap的结构,加了一个锁保持同步。
在往Segment内put的时候,会先检查是否满足扩容条件,满足则先进行扩容再插值。
一个键值对放入ConcurrentHashMap需要进行两次哈希值计算,先定位到具体的Segment,然后在Segment里面定位到具体的HashEntry数组。
jdk8 ConcurrentHashMap1.8 Part1
ConcurrentHashMap1.8 Part2
不再使用分段锁,使用cas+ synchronized的方式进行同步
有其他线程调用put、merge等方法的时候,会判断是否正在扩容。当进行扩容的时候,线程会调用helpTransfer帮助进行多线程扩容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); // 得到 hash 值 int hash = spread(key.hashCode()); // 用于记录相应链表的长度 int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 如果数组"空",进行数组初始化 if (tab == null || (n = tab.length) == 0) // 初始化数组,后面会详细介绍 tab = initTable(); // 找该 hash 值对应的数组下标,得到第一个节点 f else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 如果数组该位置为空, // 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了 // 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容 else if ((fh = f.hash) == MOVED) // 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了 tab = helpTransfer(tab, f); else { // 到这里就是说,f 是该位置的头结点,而且不为空 V oldVal = null; // 获取数组该位置的头结点的监视器锁 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表 // 用于累加,记录链表的长度 binCount = 1; // 遍历链表 for (Node<K,V> e = f;; ++binCount) { K ek; // 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } // 到了链表的最末端,将这个新值放到链表的最后面 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // 红黑树 Node<K,V> p; binCount = 2; // 调用红黑树的插值方法插入新节点 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } // binCount != 0 说明上面在做链表操作 if (binCount != 0) { // 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8 if (binCount >= TREEIFY_THRESHOLD) // 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换, // 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树 // 具体源码我们就不看了,扩容部分后面说 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } // addCount(1L, binCount); return null; }
ConcurrentHashMap的遍历
用了装饰器模式, entrySet()生成一个EntrySetView对象,里面用的还是ConcurrentHashMap自己。
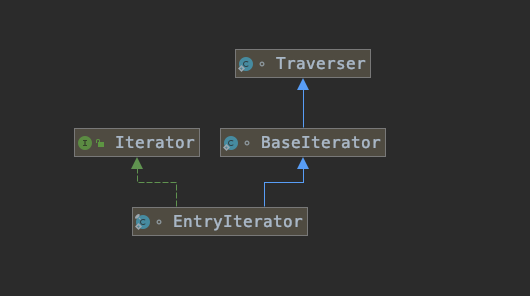
EntrySetView的iterator()方法生成EntryIterator迭代器,EntryIterator继承关系如图
Traverser类的advance()方法实现遍历时候的同步,里面调用了ConcurrentHashMap 类的tabAt()方法使用了cas进行同步
1 2 3 4 5 6 7 8 9 //ConcurrentHashMap.class public Set<Map.Entry<K,V>> entrySet() { EntrySetView<K,V> es; return (es = entrySet) != null ? es : (entrySet = new EntrySetView<K,V>(this)); } static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); }
1 2 3 4 5 6 7 //EntrySetView.class(内部类) public Iterator<Map.Entry<K,V>> iterator() { ConcurrentHashMap<K,V> m = map; Node<K,V>[] t; int f = (t = m.table) == null ? 0 : t.length; return new EntryIterator<K,V>(t, f, 0, f, m); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static class Traverser<K,V> { /** * Advances if possible, returning next valid node, or null if none. */ final Node<K,V> advance() { Node<K,V> e; if ((e = next) != null) e = e.next; for (;;) { Node<K,V>[] t; int i, n; // must use locals in checks if (e != null) return next = e; if (baseIndex >= baseLimit || (t = tab) == null || (n = t.length) <= (i = index) || i < 0) return next = null; if ((e = tabAt(t, i)) != null && e.hash < 0) { if (e instanceof ForwardingNode) { tab = ((ForwardingNode<K,V>)e).nextTable; e = null; pushState(t, i, n); continue; } else if (e instanceof TreeBin) e = ((TreeBin<K,V>)e).first; else e = null; } if (stack != null) recoverState(n); else if ((index = i + baseSize) >= n) index = ++baseIndex; // visit upper slots if present } } }
Fail fast / Fail safe 快速失败(fail—fast) 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
安全失败(fail—safe) 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。