Raft简介
Raft也是一个一致性算法,和Paxos目标相同。但它还有另一个名字-易于理解的一致性算法。
Paxos和Raft都是为了实现一致性产生的。这个过程如同选举一样,参选者需要说服大多数选民(服务器)投票给他,一旦选定后就跟随其操作。Paxos和Raft的区别在于选举的具体过程不同。
基本概念
Raft协议将Server进程分成三类,分别是Leader,Candidate,Follower。
一个Server进程在某一时刻,只能是其中一种类型,但这不是固定的。不同的时刻,它可能是有不同的类型。
在一个由 Raft 协议组织的集群中有三类角色:
- Leader(领袖)
- Follower(群众)
- Candidate(候选人)
Term: 在Raft协议中,将时间分成了一些任意长度的时间片,称为term,term使用连续递增的编号的进行识别。
每一个term都从新的选举开始,candidate们会努力争取称为leader。一旦获胜,它就会在剩余的term时间内保持leader状态,在某些情况下选票可能被多个candidate瓜分,形不成多数派,因此term可能直至结束都没有leader,下一个term很快就会到来重新发起选举。
正常运行的情况下,会有一个leader,其他全为follower,follower只会响应leader和candidate的请求,而客户端的请求则全部由leader处理,即使有客户端请求了一个follower也会将请求重定向到leader。candidate代表候选人,出现在选举leader阶段,选举成功后candidate将会成为新的leader。
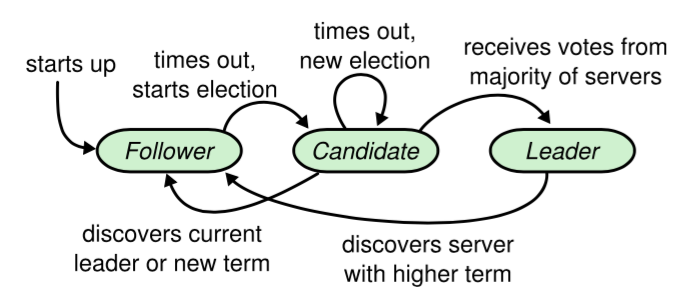
Leader选举过程
Raft通过心跳机制发起leader选举。节点都是从follower状态开始的,如果收到了来自leader或candidate的RPC,那它就保持follower状态,避免争抢成为candidate。Leader会发送空的AppendEntries RPC作为心跳信号来确立自己的地位,如果follower一段时间(election timeout)没有收到心跳,它就会认为leader已经挂了,发起新的一轮选举。
选举发起后,一个follower会增加自己的当前term编号并转变为candidate。它会首先投自己一票,然后向其他所有节点并行发起RequestVote RPC,之后candidate状态将可能发生如下三种变化:
- 赢得选举,成为leader: 如果它在一个term内收到了大多数的选票,将会在接下的剩余term时间内称为leader,然后就可以通过发送心跳确立自己的地位。(每一个server在一个term内只能投一张选票,并且按照先到先得的原则投出)
- 其他server成为leader:在等待投票时,可能会收到其他server发出AppendEntries RPC心跳信号,说明其他leader已经产生了。这时通过比较自己的term编号和RPC过来的term编号,如果比对方大,说明leader的term过期了,就会拒绝该RPC,并继续保持候选人身份; 如果对方编号不比自己小,则承认对方的地位,转为follower.
- 选票被瓜分,选举失败: 如果没有candidate获取大多数选票, 则没有leader产生, candidate们等待超时后发起另一轮选举. **为了防止下一次选票还被瓜分,必须采取一些额外的措施, raft采用随机election timeout的机制防止选票被持续瓜分.**通过将timeout随机设为一段区间上的某个值, 因此很大概率会有某个candidate率先超时然后赢得大部分选票.
参考
参考redis集群模式下的故障转移,就是用的raft算法。