常见应用场景
Redis可以做什么?
- 记录帖子的点赞数、评论数和点击数 (hash)。
- 记录用户的帖子 ID 列表 (排序),便于快速显示用户的帖子列表 (zset)。
- 记录帖子的标题、摘要、作者和封面信息,用于列表页展示 (hash)。
- 记录帖子的点赞用户 ID 列表,评论 ID 列表,用于显示和去重计数 (zset)。
- 缓存近期热帖内容 (帖子内容空间占用比较大),减少数据库压力 (hash)。
- 记录帖子的相关文章 ID,根据内容推荐相关帖子 (list)。
- 如果帖子 ID 是整数自增的,可以使用 Redis 来分配帖子 ID(计数器)。
- 收藏集和帖子之间的关系 (zset)。
- 记录热榜帖子 ID 列表,总热榜和分类热榜 (zset)。
- 缓存用户行为历史,进行恶意行为过滤 (zset,hash)。
HyperLoglog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
1 | pfadd 增加计数,将用户id加到里面,可以统计某个页面一天被多少用户访问过 |
使用场景
一般用于UV统计需求。
布隆过滤器
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤 器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
布隆过滤器可以理解为一个不怎么精确的 set 结构,当布隆过滤器说某个值存在时,这个值可能不存在,当它说不存在时,那就肯定不存在。
1 | bf.add 添加元素 |
布隆过滤器原理
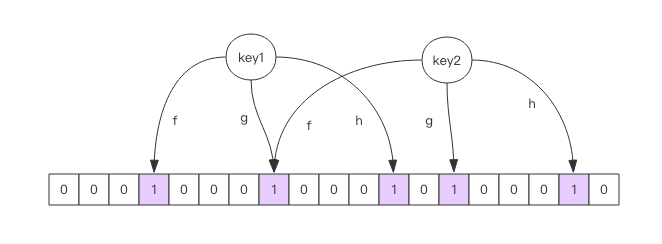
f、g、h为哈希函数。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索 引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出 来,看看位数组中这几个位置是否都位 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
使用时不要让实际元素远大于初始化大小,当实际元素开始超出初始化大小时,应该对 布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进 去 (这就要求我们在其它的存储器中记录所有的历史元素)。
应用场景
在爬虫系统中,我们需要对 URL 进行去重,已经爬过的网页就可以不用爬了。但是 URL 太多了,几千万几个亿,如果用一个集合装下这些 URL 地址那是非常浪费空间的。这 时候就可以考虑使用布隆过滤器。
布隆过滤器在 NoSQL 数据库领域使用非常广泛,我们平时用到的 HBase、Cassandra 还有 LevelDB、RocksDB 内部都有布隆过滤器结构,布隆过滤器可以显著降低数据库的 IO 请求数量。当用户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后再去磁盘进行查询。
邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器。
简单限流
系统要限定用户的某个行为在指定的时间里只能允许发生N次。
用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个 key 保存下来。同一个用户同一种行为用一个 zset 记录。value用行为的时间戳。
每一个行 为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。
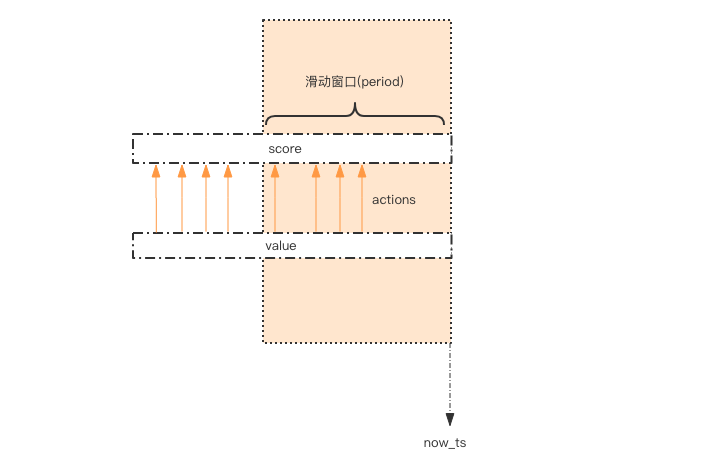
此方案不适合场景
比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流 的,因为会消耗大量的存储空间
GeoHash
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现 摩拜单车「附近的 Mobike」、美团和饿了么「附近的餐馆」这样的功能了。
如果要计算「附近的人」,也就是给定一个元素的坐标,然后计算这个坐标附近 的其它元素,按照距离进行排序,该如何下手?
GeoHash 算法
GeoHash 算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一 条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。当我们想要计算「附 近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行 了。
设想一个正方形的蛋糕摆在你面前,二刀下去均分 分成四块小正方形,这四个小正方形可以分别标记为 00,01,10,11 四个二进制整数。然后对 每一个小正方形继续用二刀法切割一下,这时每个小小正方形就可以使用 4bit 的二进制整数 予以表示。然后继续切下去,正方形就会越来越小,二进制整数也会越来越长,精确度就会 越来越高。
GeoHash 算法会继续对这个整数做一次 base32 编码 (0-9,a-z 去掉 a,i,l,o 四个字母) 变 成一个字符串。
在 Redis 里面,经纬度使用 52 位的整数进行编码,放进了 zset 里面,zset 的 value 是元素的 key,score 是 GeoHash 的 52 位整数值。
在使用 Redis 进行 Geo 查询时,我们要时刻想到它的内部结构实际上只是一个 zset(skiplist)。通过 zset 的 score 排序就可以得到坐标附近的其它元素 (实际情况要复杂一 些,不过这样理解足够了),通过将 score 还原成坐标值就可以得到元素的原始坐标。
redis分布式锁实现
redis分布式锁的实现 主要依赖SET命令
1 | SET key value [EX seconds] [PX milliseconds] [NX|XX] |
单机redis
1 |
|
- 通过SET命令 获取锁,key为锁id,value为随机值
- 释放锁的时候,先判断锁是否为之前获取到的锁,除了检查锁id外 还需要检查锁的随机值。如果都相同,说明这把锁没有其他线程抢占,可以删除释放。
RedLock
建议直接阅读redis分布式锁官方文档
算法很易懂,起始5(n>=3)个master节点,分布在不同的机房尽量保证可用性。为了获得锁,client 会进行如下操作:
- 得到当前的时间,微妙单位
- 尝试顺序地在 5 个实例上申请锁,需要使用相同的key 和 random value。客户端申请锁的时间需要小于锁的自动释放时间。如果实例不可用的话(请求超时),我们需要尽快请求下一个redis实例。
- 当 client 在大于等于3(票数过半)个 master 上成功申请到锁的时候,它会计算申请锁消耗了多少时间(这部分消耗的时间采用获得锁的当下时间减去第一步获得的时间戳得到),如果锁的持续时长(lock validity time)比流逝的时间多的话,那么锁就真正获取到了。
- 如果锁申请到了,那么锁真正的有效时间为步骤三中计算出来的时间。
- 如果 client 申请锁失败了,那么它就会在少部分申请成功锁的 master 节点上执行释放锁的操作,重置状态
缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。(黑客可以通过缓存穿透攻击,把db打死)
解决方案
- 使用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
- 缓存空数据。如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决方案
- 通过加锁或队列的方式保证来保证不会有大量的线程对数据库一次性进行读写。(加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差)
- 过期时间+随机值,防止一次性大量缓存同时过期
- 设置过期标志更新缓存 (它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。)
缓存预热
将冷数据提前加载到缓存中,避免用户直接查库。
缓存更新
惰性更新,先查缓存,查不到缓存去读数据库,并写到缓存。
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
比较简单的实现方式是业务系统代码里面加开关,通过配置中心推配置实现降级。
热点数据
一个key的并发访问量很高
1.本地做缓存
2.通过读写分离
一致性哈希和哈希槽区别
参考redis集群
数据库 缓存读写一致性问题
双写 cache aside pattern
这是最常用最常用的pattern了。
其具体逻辑如下:
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
中间件订阅mysql binlog的方式
如果有强一致性要求
- 需要将操作串行话,使用异步队列或者消息队列来保证
- 分布式系统可能还需要考虑使用分布式锁。
常见问题QA
项目中缓存是如何使用的?为什么要用缓存?缓存使用不当会造成什么后果?
高性能,高并发。
缓存与数据库双写不一致、缓存雪崩、缓存穿透
redis 和 memcached 有什么区别?
redis 相比 memcached 来说,拥有更多的数据结构
redis 的线程模型是什么?
详见事件处理器
**为什么 redis 单线程却能支撑高并发? **
单线程避免上下文切换、io多路复用、纯内存操作、C语言实现
redis都有哪些数据类型?分别在哪些场景下使用比较合适呢?
详见数据结构
redis的过期策略能介绍一下?要不你再手写一个LRU?
详见数据库,过期策略和内存淘汰策略要分清楚
怎么保证redis是高并发以及高可用的?(redis如何通过读写分离来承载读请求QPS超过10万+?)
redis主从架构、读写分离
哨兵机制保证高可用
redis主从架构下如何才能做到99.99%的高可用性?
哨兵机制
redis哨兵主备切换的数据丢失问题:异步复制、集群脑裂
min-slaves选项 参考replication
怎么保证redis挂掉之后再重启数据可以进行恢复?
redis数据持久化
你能聊聊redis cluster集群模式的原理吗?
见集群篇
redis如何在保持读写分离+高可用的架构下,还能横向扩容支撑1T+海量数据
Twemproxy codis 或者redis cluster
数据分布算法:hash+一致性hash+redis cluster的hash slot
redis cluster的核心原理分析
见集群篇
你能说说我们一般如何应对缓存雪崩以及穿透问题吗?
如何保证缓存与数据库双写时的数据一致性?
你能说说redis的并发竞争问题该如何解决吗?
分布式锁。
你们公司生产环境的redis集群的部署架构是什么样的?