消费者类型
- 独立消费者:单独消费,精确控制消费
- 消费者组:通过一个或多个消费者,对topic进行消费
订阅topic
消费者组订阅topic
消费者组订阅topic方式有以下两种
- 指定topic列表
- 通过正则表达式订阅topic
消费者组和分区的关系
消费者以组的名义订阅主题,主题有多个分区,消费者组中有多个消费者实例,那么消费者实例和分区之前的对应关系是怎样的呢?换句话说,就是组中的每一个消费者负责那些分区,这个分配关系是如何确定的呢?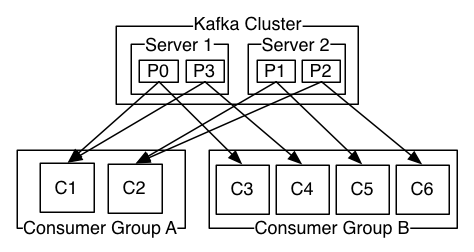
同一时刻,一条消息只能被组中的一个消费者实例消费。
如果分区数大于或者等于组中的消费者实例数,那自然没有什么问题,无非一个消费者会负责多个分区(PS:当然,最理想的情况是二者数量相等,这样就相当于一个消费者负责一个分区)
如果消费者实例的数量大于分区数,那么按照默认的策略(PS:之所以强调默认策略是因为你也可以自定义策略),有一些消费者是多余的,一直接不到消息而处于空闲状态。
假设通过自定义策略,同一个group,多个消费者负责同一个分区,那么会有什么问题呢?
消费顺序无法保证,消息重复。因为Group的对应分区的offset,没有加锁,就行多线程问题一样,
Kafka顺序消费实现
Kafka目前只提供单个分区内的消息顺序,而不会维护全局的消息顺序。
独立消费者订阅topic
独立消费者订阅topic需要指定到分区级别,而且需要用特殊的订阅api。
位移管理
初始化offset
auto.offset.reset
该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下(因消费者长 时间失效,包含偏移量的记录已经过时并被删除)该作何处理。它的默认值是 latest,在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之 后生成的记录)。另一个值是 earliest,在偏移量无效的情况下,消费者将从起始位置(当前日志的起始位置,太遥远的数据可能已经删除)读取分区的记录。
offset保存
对于消费者端的offset,kafka是让consumer自己保存的,并且引入了checkpoint机制,定期对offset进行持久化。
自己保存offset好处如下
- 减少了broker端的复杂性,broker只需要返回consumer要拉取的数据就行
- 简化ack机制,checkpoint机制对offset进行持久化,来代替ack。
- broker不用保存consumer group的消费进度,始终是无状态的,方便扩展
Kafka consumer在内部使用一个map来保存其订阅 topic所属分区的 offset。
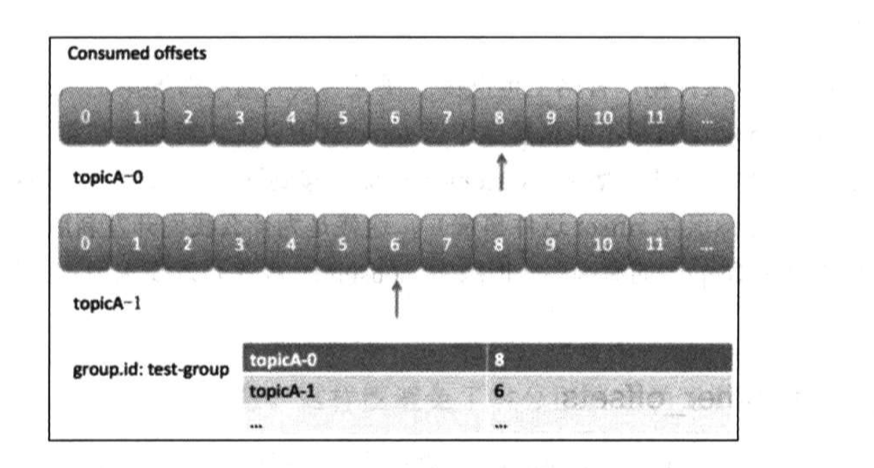
位移提交
旧版本consumer会定期将位移信息提交到zk上。
1 | /consumer/<group.id>/offsets/<topic>/<partitionId> |
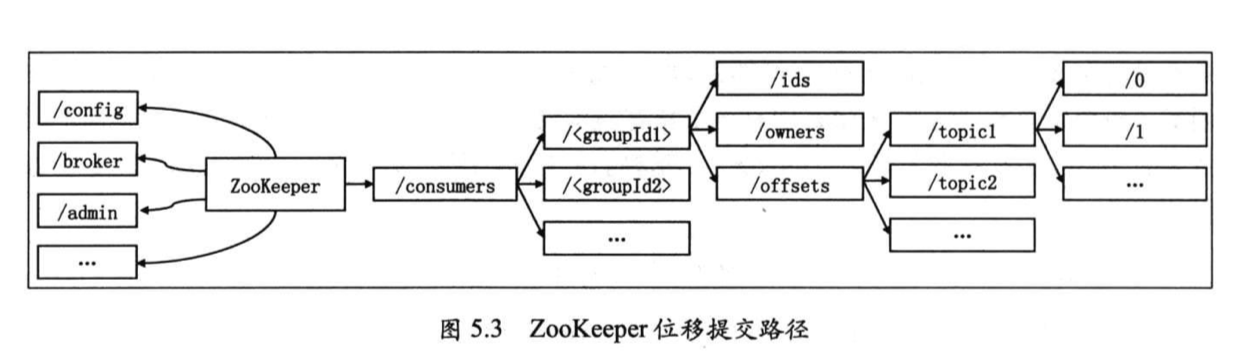
随着 Kafka consumer在实际场景的不断应用,社区发现旧版本 consumer把位移提交到ZooKeeper的做法并不合适。 ZooKeeper本质上只是一个协调服务组件,它并不适合作为位移信息的存储组件,毕竟频繁高并发的读/写操作并不是 ZooKeeper擅长的事情。
新版本方案 __consumer_offsets
__consumer_offsets是kafka内部的一个topic,日志文件里面记录了group consumer消费的offset。大致如下

key就是一个三元组: group id+ topic+分区号,而value就是 offset的值。
每当更新同一个key的最新offset值时,该topic就会写入一条含有最新offset的消息,同时Kaka broker会定期地对该topic执行压实操作(compact),即为每个消息key只保存含有最新offset的消息。这样既避免了对分区日志消息的修改,也控制住了consumer offsets topic总体的日志容量,同时还能实时反映最新的消费进度。
考虑到一个Kaka生产环境中可能有很多consumer或consumer group,如果这些 consumer同时提交位移,则必将加重 consumer offsets的写入负载,因此社区特意为该topc创建了50个分区,并且对每个group id做哈希求模运算,从而将负载分散到不同的_ consumer offsets分区上。
位移提交
消息交付语义:
- 最多一次(at most once):消息可能丢失,但不会重复。(消费之前提交位移)
- 最少一次(at last once):消息不会丢失,但可能重复。(消费之后提交位移)
- 精确一次(exactly once):消息一定会被处理且只会被处理一次。
位移提交方式:
- 手动提交
- 自动提交
消费者组重平衡
rebalance概览
对于每个组而言, Kafka的某个broker会被选举为组协调者( group coordinator)。 coordinator负责对组的状态进行管理,它的主要职责就是当新成员到达时促成组内所有成员达成新的分区分配方案,即 coordinator负责对组执行 rebalance操作。
触发条件
- 组成员发生变更,比如新 consumer加入组,或已有 consumer主动离开组,再或是已有 consumer崩溃时则触发 rebalance
- 组订阅topic数发生变更,比如使用基于正则表达式的订阅,当匹配正则表达式的新topic被创建时则会触发 rebalance.
- 组订阅 topIc的分区数发生变更,比如使用命令行脚本增加了订阅 topic的分区数
分区分配方案
kafka的consumer默认提供了三种分区策略,自己也可以实现分区策略。
- range策略:将单个 topic的所有分区按照顺序排列,然后把这些分区划分成固定大小的分区段并依次分配给每个 consumer
- round- robin策略:把所有 topic的所有分区顺序摆开,
然后轮询式地分配给各个 consumer。 - sticky策略:具体实现需要看源码 找材料补充。
rebalance generation
即分区方案的版本号。每次重平衡后都会自增1。
Kaka引入 consumer generation主要是为了保护 consumer group的,特别是防止无效 offset提交。比如上一届的 consumer成员由于某些原因延迟提交了oset,但 rebalance之后该goup产生了新一届的 group成员,而这次延迟的oset提交携带的是旧的 generation信息,因此这次提交会被 consumer group拒绝。
rebalance流程
consumer group分区分配方案是在consumer端执行的。
参考书籍
Apache kafka实战
Kafka权威指南